Screwing up my page tables
Reading time: 20 minutes
Table of contents
✱ Note
Recently, the epic yak shave that is my life dragged me down into oblong pits of page table corruption. I’ve made it out the other side, with a primary takeaway of “how the hell did this ever work?”, followed closely by “what the hell is still hiding?”.
Picture this: you’re carefree, healthy, “hey, I should rewrite axle’s network stack in Rust!”. Sinister snap of the violin. Sad oboe, crying clown.
OK, this can’t be too bad. Let’s start with the basics: we’ll fire up the network card driver to jog our memory about where we left things off.
userspace/realtek_8139_driver/realtek_8139_driver.c
typedef struct rtl8139_state {
// Configuration encoded into the device
uint8_t tx_buffer_register_ports[4];
uint8_t tx_status_command_register_ports[4];
// Configuration read from PCI bus
uint32_t pci_bus;
uint32_t pci_device_slot;
uint32_t pci_function;
uint32_t io_base;
// Configuration assigned by this driver
uint32_t receive_buffer_virt;
uint32_t receive_buffer_phys;
uint32_t transmit_buffer_virt;
uint32_t transmit_buffer_phys;
// Current running state
uint8_t tx_round_robin_counter;
uintptr_t rx_curr_buf_off;
} rtl8139_state_t;Right off the bat, we can see the pointer fields are expecting a 32-bit address space. I clearly never updated this component after upgrading axle to support x86_64.
Hopefully this component won’t just silently run into bugs on x86_64, though? Let’s keep looking.
void realtek_8139_init()userspace/realtek_8139_driver/realtek_8139_driver.c
// Set up RX and TX buffers, and give them to the device
uintptr_t rx_buffer_size = 8192 + 16 + 1500;
Deprecated("revisit");
//amc_physical_memory_region_create(rx_buffer_size, &virt_memory_rx_addr, &phys_memory_rx_addr);
Ah ha! Thanks past-me. This driver wants to call amc_physical_memory_region_create(), but I left myself a quick note that this code path needs another look. amc_physical_memory_region_create() allows the caller to allocate a region of physically contiguous memory, and I can see that I removed this capability from axle’s physical memory allocator sometime past. I inserted assertions so that any code path that tries to allocate a physically contiguous regions will alert me, upon execution, that the time has come for more physical memory allocator work.
Well, the time has come for more physical memory allocator work. The current design, implemented in C, just maintains a stack of free physical frames. It’s a bit difficult to identify and allocate contiguous regions with just a stack for storage, and adjusting our design will make things a lot easier for us. Let’s reserve a region for contiguous allocations upon startup, and allocate from it separately.
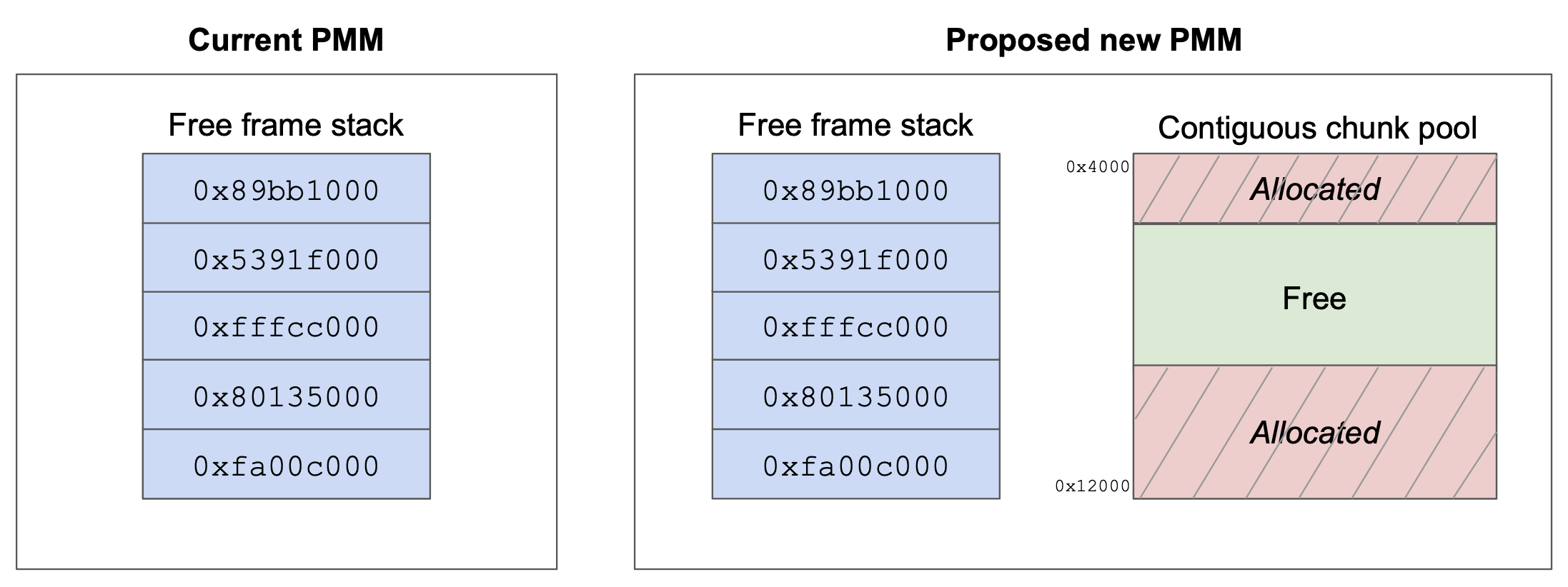
However, I can’t be bothered to do it in C.
Rust to the ruscue
Following my new SOP, I decided to rewrite my kernel-module-du-jour in Rust, and make further improvements on the module from there.
No worries, this module should be pretty simple! Let’s get started by making just a one-to-one replacement to the C API. Then, we can add our contiguous chunk pool once we’re sure the Rust-based module is working as intended.
kernel/kernel/pmm/pmm.h
void pmm_init(void);
uintptr_t pmm_alloc(void);
void pmm_free(uintptr_t frame_addr);The interface to the physical memory allocator is pretty straightforward, as is its work:
- Upon boot in
pmm_init(), read the UEFI-provided memory map to discover physical memory regions. - For all the regions that are marked in the memory map as ‘usable’, excluding specific frames we intentionally exclude from the physical memory allocator✱, track the frames in the allocator’s free-frames stack.
- When an allocation is requested via
pmm_alloc(), pop a free frame from the free-frames stack. - When a frame is freed via
pmm_free(), push the frame back onto the free-frames stack.
✱ Note
This can be implemented in well under a couple of hundred lines, and there’s nothing snazzy about it. Imagine my horror, then, when I turned on the new Rust-based allocator and started getting page faults during boot!
Bug #1: Buffer overflow in SMP bootstrap setup
Debugging memory bugs in kernel-space is never fun, and at the worst of times can be an outright nightmare. Timing and different sequencing of events during testing sometimes preclude bugs from manifesting, making it difficult to isolate whatever is going wrong.
We know that the bug doesn’t manifest when using the C allocator, and does when using the Rust allocator. Maybe these allocators have slightly different allocation patterns?
// Allocation pattern for the C allocator
pmm_alloc() = 0x0000000000000000
pmm_alloc() = 0x0000000000001000
pmm_alloc() = 0x0000000000002000
pmm_free( 0x00000000be411000)
pmm_alloc() = 0x00000000be411000
pmm_alloc() = 0x0000000000003000
pmm_alloc() = 0x0000000000004000
// Allocation pattern for the Rust allocator
pmm_alloc() = 0x0000000000000000
pmm_alloc() = 0x0000000000001000
pmm_alloc() = 0x0000000000002000
pmm_free( 0x00000000be411000)
pmm_alloc() = 0x0000000000003000
pmm_alloc() = 0x0000000000004000
pmm_alloc() = 0x0000000000005000That’s interesting! The C allocator operates in LIFO✱: it enqueues freed frames to the top of its stack, such that the next allocation yields whatever frame was last freed. The Rust allocator, by contrast, operates in FIFO: freed frames are pushed to the back, and we’ll only see them again once we exhaust all the frames we enqueued at the beginning.
✱ Note
Although noteworthy, the difference in behavior isn’t surprising: in the C allocator, I’m using a small handwritten stack, which naturally has LIFO semantics. In the Rust allocator, I’m using heapless::Queue, which is FIFO by design. The difference in access pattern isn’t a problem in-and-of itself, but the fact that different frames are now being used for early-boot structures is causing some deeper bug to crawl out the shadowy depths.
I started hacking at the codebase, lobbing off chunks of functionality left and right, haphazardly disabling subsystems within which the bug could nest. Eventually, I managed to isolate a reproducing case to within SMP bringup.
As a refresher✱, each time we boot another core on the machine during symmetric multiprocessing bringup, the core will invariably✱ start booting in 16-bit mode, and we’ll need to manually help it go through the motions of enabling 32-bit and 64-bit mode (or ’long mode’). Booting into 16-bit mode imposes some constraints: particularly, we need to have some code at a known physical memory address below the 1MB mark that the core can begin executing from. In axle, frame 0x8000 is used for this purpose, and is referred to as the SMP bootstrap code frame. axle places a hand-coded assembly routine into this frame that performs the long walk to long mode.
✱ Note
✱ Note
To make the transition to 64-bit mode more convenient, several of the data structures that this program needs are placed into another special frame, 0x9000, which axle denotes the SMP bootstrap data frame. Specific offsets within this frame hold pointers to different data structures that the bootstrap program needs while transitioning to 64-bit mode, such as:
- A 32-bit GDT
- A 64-bit GDT containing ’low memory’ pointers
- A 64-bit GDT containing ‘high memory’ pointers
- A 64-bit PML4
- A 64-bit IDT
- A high-memory stack pointer
- A high-memory entry point to jump to once the bootstrap program completes
kernel/kernel/ap_bootstrap.h
#define AP_BOOTSTRAP_PARAM_OFFSET_PROTECTED_MODE_GDT 0x0
#define AP_BOOTSTRAP_PARAM_OFFSET_LONG_MODE_LOW_MEMORY_GDT 0x100
#define AP_BOOTSTRAP_PARAM_OFFSET_LONG_MODE_HIGH_MEMORY_GDT 0x200
#define AP_BOOTSTRAP_PARAM_OFFSET_PML4 0x300
#define AP_BOOTSTRAP_PARAM_OFFSET_IDT 0x400
#define AP_BOOTSTRAP_PARAM_OFFSET_C_ENTRY 0x500
#define AP_BOOTSTRAP_PARAM_OFFSET_STACK_TOP 0x600While setting up the SMP bootstrap data frame, the kernel will create these structures, and copy the pointers to their expected locations within the data frame. For example, here’s how the kernel sets up the C entry point address:
kernel/kernel/smp.c
// Copy the C entry point
uintptr_t ap_c_entry_point_addr = (uintptr_t)&ap_c_entry;
memcpy((void*)PMA_TO_VMA(AP_BOOTSTRAP_PARAM_C_ENTRY), &ap_c_entry_point_addr, sizeof(ap_c_entry_point_addr));Here’s how the kernel sets up the IDT address:
kernel/kernel/smp.c
// Copy the IDT pointer
idt_pointer_t* current_idt = kernel_idt_pointer();
// It's fine to copy the high-memory IDT as the bootstrap will enable paging before loading it
memcpy(
(void*)PMA_TO_VMA(AP_BOOTSTRAP_PARAM_IDT),
current_idt,
sizeof(idt_pointer_t) + current_idt->table_size
);Wait, what? We’re copying sizeof(idt_pointer_t) + current_idt->table_size bytes, but no one was expecting us to copy the whole table! We’re only meant to be copying a pointer to the table.
Double-checking the bootstrap program, we definitely didn’t expect this; the bootstrap program just expects a pointer, not the full table data.
ap_bootstrap.s.x86_64.arch_specific
idt_ptr: dd 0x9400
; Load the IDT
mov eax, [$idt_ptr]
lidt [eax]Having a closer look at current_idt->table_size, we find that this table occupies 0xfff bytes. This means that our flow above will write outside the allowed frame, which ends at 0xa000, overwriting whatever’s occupying 0xa000 to 0xa408 with the back half of the kernel’s interrupt descriptor table. This overflow didn’t cause any visible errors with our previous frame allocation pattern, so it didn’t come up before. However, with our new allocation pattern, this overflow is overwriting data in a way that leads directly to a page fault. Let’s fix the overflow:
kernel/kernel/smp.c
// Copy the IDT pointer
idt_pointer_t* current_idt = kernel_idt_pointer();
// It's fine to copy the high-memory IDT as the bootstrap will enable paging before loading it
memcpy(
(void*)PMA_TO_VMA(AP_BOOTSTRAP_PARAM_IDT),
current_idt,
sizeof(idt_pointer_t)
);Lesson
Changing our frame allocation strategy, an access pattern detail that ideally shouldn’t drastically impact system behavior, caused several low-level memory bugs to come to light. Maybe we could intentionally randomize our frame allocation patterns, so we can intentionally search out bugs in this class. We could also allow setting a seed for this randomization, to enable reproducible scenarios.
One bug squashed, let’s keep going!
Bug #2: Overwriting paging structures due to a truncated pointer
We’ve progressed a bit further into boot, but now we see something really odd. At some point, we get a page fault. However, the faulting address points to a location that should obviously be a valid memory location, such as bits of the kernel that are mapped into every address space. Furthermore, this page fault is much more resistant to this slice-things-off-until-the-bug-remains approach that we used above. The exact location of the page fault seems to jump around between different runs. We’re going to have to solve this quick, as if I bite my fingernails any shorter I’ll lose my elbows.
I fire up gdb and get to work tracking down what’s going wrong. Eventually, I set a breakpoint in _handle_page_fault() and investigate the virtual address space state.
Here’s what a normal virtual address space layout looks like for an early-boot snapshot:
0x0000000000000000 - 0x0000001000000000 -rw
0xffff800000000000 - 0xffff801000000000 -rw
0xffff900000000000 - 0xffff900000045000 -rw
0xffffa00000000000 - 0xffffa00000001000 -rw
0xffffffff80000000 - 0xffffffff8221a000 -rwAll the ranges here match our expectations, and are further specified in memory_map.md:
0x0000000000000000 - 0x0000001000000000: Early-boot physical RAM identity-map0xffff800000000000 - 0xffff801000000000: High-memory physical RAM remap0xffff900000000000 - 0xffff900000045000: Kernel heap0xffffa00000000000 - 0xffffa00000001000: CPU core-specific storage page0xffffffff80000000 - 0xffffffff8221a000: Kernel code and data
The virtual address space state once our page fault breakpoint triggers:
0x0000000000000000 - 0x00000000bee00000 -rw
0x00000000bee00000 - 0x00000000bf000000 -r-
0x00000000bf000000 - 0x00000000bfa5b000 -rw
0x00000000bfa5b000 - 0x00000000bfa5c000 -r-
0x00000000bfa5c000 - 0x00000000bfa5e000 -rw
0x00000000bfa5e000 - 0x00000000bfa5f000 -r-
0x00000000bfa5f000 - 0x00000000bfa61000 -rw
0x00000000bfa61000 - 0x00000000bfa63000 -r-
0x00000000bfa63000 - 0x00000000bfa65000 -rw
0x00000000bfa65000 - 0x00000000bfa66000 -r-
0x00000000bfa66000 - 0x00000000bfa68000 -rw
0x00000000bfa68000 - 0x00000000bfac3000 -r-
0x00000000bfac3000 - 0x00000000bfadf000 -rw
0x00000000bfadf000 - 0x00000000bfae0000 -r-
0x00000000bfae0000 - 0x00000000bfae3000 -rw
0x00000000bfae3000 - 0x00000000bfae4000 -r-
0x00000000bfae4000 - 0x00000000bfae7000 -rw
0x00000000bfae7000 - 0x00000000bfae8000 -r-
0x00000000bfae8000 - 0x00000000bfaeb000 -rw
0x00000000bfaeb000 - 0x00000000bfaed000 -r-
0x00000000bfaed000 - 0x00000000bfc00000 -rw
0x00000000bfc00000 - 0x00000000bfe00000 -r-
0x00000000bfe00000 - 0x0000001000000000 -rwThat looks… terrifying, not to mention nonsensical. What are all these regions? Why are they in low memory? Why does the size of one region correspond to the base address of the next region? What am I doing with my life?
Things start to feel a lot more manageable once you realize that the nonsensical address space mappings we’ve listed above might be the result of our paging structures themselves being overwritten due to incorrect memory accesses. If you overwrite your own description of how the virtual address space should be laid out, you can bet you’re going to get weird violations on addresses that should obviously be valid.
This really takes the sting out of these scary faults, and now we can get to work tracking down the exact subsystem responsible for the corrupted page tables.
I notice something supremely odd: when creating the structure backing a new process, the kernel heap appears to be returning addresses in very low memory, rather than addresses above 0xffff900000000000 (the base of the kernel heap).
task_small_t* _thread_create(void*, uintptr_t, uintptr_t, uintptr_t)kernel/kernel/multitasking/tasks/task_small.c
task_small_t* new_task = kmalloc(sizeof(task_small_t));
printf("Debug: Allocated new task 0x%p\n", new_task);syslog.log
Cpu[0],Pid[10],Clk[4661]: [10] Debug: Allocated new task 0x0000000000002110
Cpu[0],Pid[10],Clk[4662]: [10] Debug: Allocated new task 0x00000000000045c0Okay, this is starting to make sense!
- For ~some reason~, allocating a new task block returns an address in low memory.
- When we populate this task block, we overwrite this low memory.
- Paging structures are some of the first frames allocated by the PMM, and therefore reside in low memory.
- Paging structures get overwritten with contextually bogus data, resulting in mega-invalid virtual address spaces and page access violations at addresses that should be valid.
The big question now is, why is the kernel heap returning addresses in low memory, rather than addresses within the kernel heap?
After poking around within gdb further, it appears that the return value from kmalloc() is a valid pointer within the heap. This pointer is stored in $rax, then… is truncated by the next instruction?! Let’s take a look at the assembly.
task_small_t* _thread_create(void*, uintptr_t, uintptr_t, uintptr_t)axle.bin
mov edi, 0xf0
mov eax, 0x0
call kmalloc
cdqeHmm, I’m not familiar with cdqe. A quick search reveals that it sign-extends the lower 4 bytes into the full 8 bytes. Ah ha! A flash of insight illuminates my grasping waddles. Could it be that kmalloc() is implicitly defined at the call site, so the compiler assumes the return type is a 32-bit int, chucking out the top half of the pointer value?
Indeed, this is exactly what’s going on. A simple #include at the top of task_small.c fixes this right up, and no more page table corruption for us.
I’ll finish this section with the unedited notes I took as I debugged this.
task_small_t* _thread_create(void*, uintptr_t, uintptr_t, uintptr_t)kernel/kernel/multitasking/tasks/task_small.c
task_small_t* new_task = kmalloc(sizeof(task_small_t));
// This is giving out addresses in very low pages?!
// Allocated new_task 0000000000002110
// Allocated new_task 00000000000045c0
// These frames are being used to hold paging structures, and when they get overwritten, kaboom
// Compiler is emitting a `cltq` instruction after the call to kmalloc(),
// which truncates 0xffff900000000d70 to 0xd70
// Jesus christ, it's because kmalloc wasn't defined
Lesson
Warnings are useful, and an appetite for ignoring them will wind you up with a bellyful of pain. I enabled -Werror=implicit-function-declaration to ensure that implicitly defined functions are always a hard error, as this is evidently very dangerous: any call site invoking an implicitly defined function, expecting to receive a pointer back, is going to have a very bad time. I then cleaned up all the implicitly defined functions in the kernel.
Also, it’s not great that producing an invalid low pointer causes our paging structures to get overwritten, as these structures are essential to maintaining a system with some semblance of coherence, and their corruption makes debugging way more confusing, challenging, and unpredictable. Userspace programs generally don’t map the bottom region of the address space (or map it as inaccessible). This so-called ‘NULL region’ is very useful for debugging: it means that if a bug ever leads you to accessing low memory, you’ll get a quick crash instead of overwriting important state. This is why you get a ‘segmentation fault’ when dereferencing a NULL pointer!
Since we’re working in the context of physical memory, we don’t have the luxury of mapping frames however we like. If we want to exclude the lowest section of the address space, we have to ‘waste’ that RAM: we can’t use it for anything else. Maybe this is a worthwhile tradeoff. I’m imagining marking the lowest few frames as a ‘scribble region’: all zeroes to start, with some kind of background job that watches for if any non-zero data pops up in these frames. If it does, we know that some part of the system has accessed an invalid pointer. Since the process of accessing an invalid pointer is only possible while the kernel’s low-memory identity map is active, we could free this scribble region as soon as we disable the low-memory identity map, and give the reserved frames back to the physical memory allocator.
Surely we’re done..?
Bug #3: Overwriting paging structures due to bad pointer math in allocator
I think I’m going to throw up.
We’ve got another bug in which the paging structures in low-memory are being overwritten while cloning a virtual address space. Let’s take a look at our allocation pattern again…
pmm_alloc() = 0x0000000000000000
pmm_alloc() = 0x0000000000001000
pmm_alloc() = 0x0000000000002000
pmm_alloc() = 0x0000000000003000
pmm_alloc() = 0x0000000000004000
// Lots of output....
pmm_alloc() = 0x00000000ffffd000
pmm_alloc() = 0x00000000ffffe000
pmm_alloc() = 0x00000000fffff000
pmm_alloc() = 0x0000000000000000
pmm_alloc() = 0x0000000000001000Oh, gnarly! At first glance, our PMM is double-allocating frames; see how 0x0000000000001000 is allocated once near the beginning, then again much later on?
At closer look, the PMM starts this double-allocating as soon as the frame address ticks over to 0x0000000100000000 (ie. above 4GB). This triggers my spidey-senses that something, somewhere, isn’t handling 64-bit addresses correctly.
Indeed, I blithely translated some old code into Rust:
const FRAME_MASK: usize = 0xfffff000;
fn frame_ceil(mut addr: usize) -> usize {
if (addr & FRAME_MASK) == 0 {
// Already frame-aligned
addr
}
else {
// Drop the overflow into the frame, then add a frame
(addr & FRAME_MASK) + FRAME_SIZE;
}
}I felt pretty silly when I spotted this one. I’m actually casting off all the bits above u32::max, since the mask I’m applying is 0x00000000fffff000. Therefore, any addresses above 4GB that are enqueued get truncated to their low-memory cousins. When these truncated frame addresses get allocated, I’m telling each allocator user “no really, go ahead and write to 0x8000, it’s yours!”. This frame is already being used by something else in the system, and chaos ensues.
The fix here is really simple! I moved away from the ’enable absolute bits’ approach to a ‘disable relative bits’ approach, which automatically masks to the correct addresses regardless of the target’s word size.
rust_kernel_libs/pmm/src/lib.rs
fn page_ceil(mut addr: usize) -> usize {
((addr) + PAGE_SIZE - 1) & !(PAGE_SIZE - 1)
}Bug #4: Top portion of address space is missing due to bad math in page mapper
This one was weird. Over the course of writing the contiguous chunk pool in the new Rust-based PMM, I introduced a new piece of global state to manage the pool.
rust_kernel_libs/pmm/src/lib.rs
static mut CONTIGUOUS_CHUNK_POOL: ContiguousChunkPool = ContiguousChunkPool::new();Since this data is declared static, the storage for this structure will be reserved when the kernel is loaded into memory by axle’s UEFI bootloader✱.
✱ Note
.bss binary section”. This isn’t strictly accurate. The .bss section instructs the loader to populate the virtual address space with a zero-filled region at the specified address, but there’s no storage space reserved in the binary itself. Since the data will only exist at runtime anyway, this is a nice trick to ‘inflate’ the storage space that a binary will use upon loading, without paying that storage cost in the binary itself.As it happens, the build system ended up placing this structure at the very top of the address space reserved for axle’s kernel.

But when this code runs, we get a page fault when trying to access this structure.
syslog.log
Cpu[0],Pid[-1],Clk[0]: [-1] Page fault at 0xffffffff82217138
Cpu[0],Pid[-1],Clk[0]: |--------------------------------------|
Cpu[0],Pid[-1],Clk[0]: | Page Fault in [-1] |
Cpu[0],Pid[-1],Clk[0]: | Unmapped read of 0xffffffff82217138 |
Cpu[0],Pid[-1],Clk[0]: | RIP = 0xffffffff800d48a6 |
Cpu[0],Pid[-1],Clk[0]: | RSP = 0x00000000bfeba520 |
Cpu[0],Pid[-1],Clk[0]: |--------------------------------------|Huh, that’s odd. The bootloader sets up memory regions based on whatever is described by the kernel binary:
uint64_t kernel_map_elf(const char*, pml4e_t*, axle_boot_info_t*)bootloader/main.c
// Iterate the program header table, mapping binary segments into the virtual address space as requested
for (uint64_t i = 0; i < elf->e_phnum; i++) {
Elf64_Phdr* phdr = (Elf64_Phdr*)(kernel_buf + elf->e_phoff + (i * elf->e_phentsize));
if (phdr->p_type == PT_LOAD) {
uint64_t bss_size = phdr->p_memsz - phdr->p_filesz;
efi_physical_address_t segment_phys_base = 0;
int segment_size = phdr->p_memsz;
int segment_size_page_padded = ROUND_TO_NEXT_PAGE(phdr->p_memsz);
int page_count = segment_size_page_padded / PAGE_SIZE;
// Allocate physical memory to store the binary data that we'll place in the virtual address space
efi_status_t status = BS->AllocatePages(AllocateAnyPages, EFI_PAL_CODE, page_count, &segment_phys_base);
// Copy the binary data, and zero out any extra bytes
memcpy((void*)segment_phys_base, kernel_buf + phdr->p_offset, phdr->p_filesz);
memset((void*)(segment_phys_base + phdr->p_filesz), 0, bss_size);
// Set up the virtual address space mapping
printf("Mapping [phys 0x%p - 0x%p] - [virt 0x%p - 0x%p]\n", segment_phys_base, segment_phys_base + segment_size_page_padded - 1, phdr->p_vaddr, phdr->p_vaddr + segment_size_page_padded - 1);
map_region_4k_pages(vas_state, phdr->p_vaddr, segment_size_page_padded, segment_phys_base);
}
}When we run this, the segment containing our PMM’s new data structure appears to be mapped correctly.
syslog.log
Mapping [phys 0x00000000adcb3000 - 0x00000000addb1fff] - [virt 0xffffffff80000000 - 0xffffffff800fefff]
Mapping [phys 0x00000000abb97000 - 0x00000000adcaffff] - [virt 0xffffffff800ff000 - 0xffffffff82217fff]And yet, we get a page fault upon access! What do we see when we interrogate the actual state of the virtual address space, disregarding out intention for what the address space should look like?
0x0000000000000000 - 0x0000001000000000 -rw
0xffff800000000000 - 0xffff801000000000 -rw
0xffffffff80000000 - 0xffffffff82200000 -rwYeah, that’s it! We’re intending for data to be mapped into the virtual address space at 0xffffffff82217fff, but, for some reason, our virtual address space stops at 0xffffffff82200000. When we try to access a data structure that happens to be stored in this bad region, we get a page fault.
But why are we missing the top region of the address space? A likely suspect for investigation is the logic which sets up a virtual address space mapping based on input parameters, and indeed this is where our problems lie.
The logic within the bootloader’s that maps regions of the virtual address space looks roughly like this:
uint64_t map_region_4k_pages(pml4e_t*, uint64_t, uint64_t, uint64_t)bootloader/paging.c
int page_directory_pointer_table_idx = VMA_PML4E_IDX(vmem_start);
pdpe_t* page_directory_pointer_table = get_or_create_page_directory_pointer_table(page_directory_pointer_table_idx);
uint64_t first_page_directory = VMA_PDPE_IDX(vmem_start);
uint64_t page_directories_needed = (remaining_size + (VMEM_IN_PDPE - 1)) / VMEM_IN_PDPE;
for (int page_directory_iter_idx = 0; page_directory_iter_idx < page_directories_needed; page_directory_iter_idx++) {
int page_directory_idx = first_page_directory + page_directory_iter_idx;
uint64_t first_page_table = VMA_PDE_IDX(current_page);
uint64_t page_tables_needed = (remaining_size + (VMEM_IN_PDE - 1)) / VMEM_IN_PDE;
for (int page_table_iter_idx = 0; page_table_iter_idx < page_tables_needed; page_table_iter_idx++) {
int page_table_idx = first_page_table + page_table_iter_idx;
uint64_t first_page = VMA_PTE_IDX(current_page);
uint64_t pages_needed = (remaining_size + (VMEM_IN_PTE - 1)) / VMEM_IN_PTE;
for (int page_iter_idx = 0; page_iter_idx < pages_needed; page_iter_idx++) {
int page_idx = page_iter_idx + first_page;
mark_page_present(
page_directory_pointer_table,
page_directory_idx,
page_table_idx,
page_idx
);
}
}
}The logic above essentially has two jobs, which are being interleaved:
- Map the requested virtual address space region
- Identify which paging structures to use to map each frame
The loops above work just fine when all the paging tables we’re accessing along the way are empty. However, if one or several of the tables we’re adding data to is already partially full, the above loop won’t populate everything we requested. It’ll calculate how many tables it’d take to satisfy the request if all of those tables were empty to begin with. If some of those tables were storing some virtual address mappings to begin with, though, we won’t map as much memory as was requested, and will silently produce an unexpected virtual address space state!
The fix here is conceptually straightforward: rather than trying to compute exactly how many structures we’ll need to iterate upfront, let’s just allocate pages one-by-one until we’ve satisfied the map request, and look up the correct paging structures to map each page on the fly:
uint64_t map_region_4k_pages(pml4e_t*, uint64_t, uint64_t, uint64_t)bootloader/paging.c
uint64_t remaining_size = vmem_size;
uint64_t current_page = vmem_start;
while (true) {
// Find the correct paging structure indexes for the current virtual address
//
// Get the page directory pointer table corresponding to the current virtual address
int page_directory_pointer_table_idx = VMA_PML4E_IDX(current_page);
pdpe_t* page_directory_pointer_table = get_or_create_page_directory_pointer_table(page_directory_pointer_table_idx);
// Get the page directory corresponding to the current virtual address
int page_directory_idx = VMA_PDPE_IDX(current_page);
pde_t* page_directory = get_or_create_page_directory(page_directory_idx);
// Get the page table corresponding to the current virtual address
int page_table_idx = VMA_PDE_IDX(current_page);
pte_t* page_table = get_or_create_page_table(page_table_idx);
// Get the PTE corresponding to the current virtual address
uint64_t page_idx = VMA_PTE_IDX(current_page);
mark_page_present(
page_directory_pointer_table,
page_directory_idx,
page_table_idx,
page_idx
);
remaining_size -= PAGE_SIZE;
current_page += PAGE_SIZE;
if (remaining_size == 0x0) {
break;
}
}Bug #5: Transitive heap allocations cause crashes in the PMM
Over the course of debugging the Rust-based PMM, I naturally printed out some state at various interesting locations:
rust_kernel_libs/pmm/src/lib.rs
if !CONTIGUOUS_CHUNK_POOL.is_pool_configured() && region_size >= CONTIGUOUS_CHUNK_POOL_SIZE
{
println!("Found a free memory region that can serve as the contiguous chunk pool {base} to {}", base + region_size);
CONTIGUOUS_CHUNK_POOL.set_pool_description(base, CONTIGUOUS_CHUNK_POOL_SIZE);
// Trim the contiguous chunk pool from the region and allow the rest of the frames to
// be given to the general-purpose allocator
region_size -= CONTIGUOUS_CHUNK_POOL_SIZE;
}Upon execution, though, I would get surprising failures about an exhausted virtual address space.
syslog.log
Cpu[0],Pid[-1],Clk[0]: Found a free memory region that can serve as the contiguous chunk pool 0000000001500000 to 00000000a5f22000
Cpu[0],Pid[-1],Clk[0]: liballoc: initialization of liballoc 1.1
Cpu[0],Pid[-1],Clk[0]: Expand kernel heap by 16 pages (64kb)
Cpu[0],Pid[-1],Clk[0]: [-1] Assertion failed: VAS will exceed max tracked ranges!
Cpu[0],Pid[-1],Clk[0]: kernel/kernel/vmm/vmm.c:296Taking a peek into the virtual address space mappings like we learned above, we can see telltale signs that things have definitely gone awry.
syslog.log
0x0000000000000000 - 0x00000000bee00000 -rw
0x00000000bee00000 - 0x00000000bf000000 -r-
0x00000000bf000000 - 0x00000000bfa5b000 -rw
0x00000000bfa5b000 - 0x00000000bfa5c000 -r-
0x00000000bfa5c000 - 0x00000000bfa5e000 -rw
0x00000000bfa5e000 - 0x00000000bfa5f000 -r-
0x00000000bfa5f000 - 0x00000000bfa61000 -rw
0x00000000bfa61000 - 0x00000000bfa63000 -r-
0x00000000bfa63000 - 0x00000000bfa65000 -rw
0x00000000bfa65000 - 0x00000000bfa66000 -r-
0x00000000bfa66000 - 0x00000000bfa68000 -rw
0x00000000bfa68000 - 0x00000000bfac3000 -r-
0x00000000bfac3000 - 0x00000000bfadf000 -rw
0x00000000bfadf000 - 0x00000000bfae0000 -r-
0x00000000bfae0000 - 0x00000000bfae3000 -rw
0x00000000bfae3000 - 0x00000000bfae4000 -r-
0x00000000bfae4000 - 0x00000000bfae7000 -rw
0x00000000bfae7000 - 0x00000000bfae8000 -r-
0x00000000bfae8000 - 0x00000000bfaeb000 -rw
0x00000000bfaeb000 - 0x00000000bfaed000 -r-
0x00000000bfaed000 - 0x00000000bfc00000 -rw
0x00000000bfc00000 - 0x00000000bfe00000 -r-
0x00000000bfe00000 - 0x0000001000000000 -rwAs it turns out, the issue here is that the println!() macro transitively kicks off a heap allocation.
rust_kernel_libs/ffi_bindings/src/lib.rs
#[macro_export]
macro_rules! println {
() => ($crate::printf!("\n"));
($($arg:tt)*) => ({
let s = alloc::fmt::format(core::format_args_nl!($($arg)*));
for x in s.split('\0') {
let log = ffi_bindings::cstr_core::CString::new(x).expect("printf format failed");
unsafe { ffi_bindings::printf(log.as_ptr() as *const u8); }
}
})
}Performing a heap allocation within the physical memory manager is definitely not allowed, as this inverts the dependency tree. The physical memory manager sits at the bottom of the stack, and the virtual memory manager sits above that. The kernel heap is just a client of the virtual memory manager, which requests and frees chunks of virtual address space. In practice, trying to perform heap allocations from the physical memory allocator causes corrupted virtual address space state, and, as a result, confusing crashes. The fix for this particular case is to invoke axle’s C-based printf function directly via FFI, rather than going through the formatting machinery. Of course, this means I need to do a bit of work by hand, such as remembering to null-terminate Rust-originating strings that I pass.
rust_kernel_libs/pmm/src/lib.rs
if !CONTIGUOUS_CHUNK_POOL.is_pool_configured() && region_size >= CONTIGUOUS_CHUNK_POOL_SIZE
{
printf("Found a free memory region that can serve as the contiguous chunk pool %p to %p\n\0".as_ptr() as *const u8, base, base + region_size);
CONTIGUOUS_CHUNK_POOL.set_pool_description(base, CONTIGUOUS_CHUNK_POOL_SIZE);
// Trim the contiguous chunk pool from the region and allow the rest of the frames to
// be given to the general-purpose allocator
region_size -= CONTIGUOUS_CHUNK_POOL_SIZE;
}I do wish Rust provided some way to express and enforce that a particular module isn’t allowed to allocate!