Running axle on multiple CPUs
Reading time: 17 minutes
In the beginning, Intel created the 8086. This has been widely regarded as a bad move, but boy is it popular.
The enduring success of the 8086 has been bought on the blood altar of Compatibility: software written for the original 8086, even very low-level software that runs without any supporting OS infrastructure, must continue to function on every new x86-line CPU manufactured today✱.
✱ Note
This selling point enforces some pretty annoying constraints on both the advancement of the x86 line and on developers who need to interface directly with x86 CPUs.
CPU Modes
The 8086 was a 16-bit✱ CPU. Time and history increased the register and address space size that more contemporary software expects, but any x86 CPU today still needs to be able to run 16-bit software. What does this mean in practice? Since the 8086 doesn’t ‘know’ about the future 32- and 64-bit modes, the responsibility is on the newer software to alert the chip: “Hello, I’m software written in the 21st century, please give me the good stuff!”. 16-bit mode is used by default and only disabled when the software explicitly alerts the CPU that it’s new enough.
✱ Note
This same idea applies to 32-bit mode, by the way. Once 16-bit mode (Real Mode, if you’re cool) has been exited, you stay in a compatibility 32-bit mode (Protected Mode). If the software can take the heat, it does a final✱ jump to 64-bit mode (Long Mode).
✱ Note
This isn’t theoretical! Every time each and every time one of the billions of x86 CPUs in the world boots up, the OS software has to hand-hold it through 50 years of history, turning on each decade’s new modes, whispering to the CPU yes, it’s okay, we’re in the future now: you can use your wide registers, your expanded address spaces, your extra cores.
The springboard through history of 16-bit, to 32-bit, to 64-bit, is one of the earliest responsibilities of any system, and parts of it are typically handled by the bootloader. For example, GRUB will do the OS the courtesy of transitioning from Real Mode to Protected Mode, so the OS doesn’t need to worry about it.
Unfortunately, GRUB doesn’t help us with the transition from Protected Mode to Long Mode. This was one of my motivations for moving away from GRUB in late 2021. In its place, I introduced a custom UEFI bootloader. This isn’t as scary as it sounds, and has a pretty great effort ⇔ hacker cred ratio. Firstly, this gave me a lot more control over axle’s boot environment, and allowed me to do many nice things such as set a custom screen resolution during the bootloader’s work, based on configuration files within axle’s disk image. More relevantly, though, UEFI natively provides a 64-bit operating environment for the bootloader: not only does the OS kernel not need to worry about how to jump to Long Mode, not even the bootloader needs to know how to do it! Sounds great, right?
Wrong. When has it ever been easy?
Oh.
UEFI is made up of a few parts:
- The firmware that is flashed to the motherboard.
- This is the ’true’✱ first software component that runs, prior to the bootloader itself. It provides the UEFI execution environment for UEFI ‘apps’. While most of the time this will immediately hand over control to whatever bootloader is installed, this can also have its own shell environment that can be used to launch UEFI apps. If you’re ever pressed F12 to configure startup options, you’ve interacted directly with your motherboard’s UEFI firmware.
✱ Note
- The bootloader that loads the OS kernel
- From the perspective of the motherboard firmware, this is just a semi-special UEFI app. What’s special about it? It takes control of the system and never returns back to the UEFI firmware shell.
The promise of UEFI is that the firmware will handle the transition to Long Mode for you, and the bootloader and kernel can immediately start execution in a Long Mode environment. This is pretty much true for the moment, but it falls apart below the fold. To see why, we need to take a detour…
Multithreading
Users, with their relentless demands, sometimes expect to be able to do more than one thing at a time. This implies the need for some kind of concurrent execution of software. How can we achieve this when the CPU contains just a single core, as has been the standard for the majority of x86’s history?
Operating systems use a pretty standard trick here. Rather than truly having two streams of instructions executing at a time, the OS kernel will trigger a ‘context switch’ every few milliseconds. This context switch will save all the necessary state of the currently running stream of instructions, and restore the state from a previously-running stream of instructions. At human-scale measured in hundreds and thousands of milliseconds, this continuous swapping within a fundamentally single-threaded system can provide the illusion of concurrent execution, and the reality of high-level multitasking.
Over the past two decades, though, CPUs have grown to embed multiple cores within a single package, unleashing the possibility of true concurrent execution of instruction streams. Rather than needing to time-share a single core among 2 threads of execution, the 2 threads can be scheduled on physically distinct cores.
However, merely running a newer CPU isn’t enough for an OS to profit from this capability: the OS needs to be ‘multiprocessing-aware’, and have all the necessary infrastructure to work with, and to distribute work to, other cores on the system. Each core is typically ‘symmetric’ with all the others, meaning the cores are pretty much interchangeable: work can be scheduled on any core and the OS doesn’t need to mind too much about which core is used for what.
This raises some pretty natural questions. For example, if we’re not running a multiprocessing-aware OS, but our physical CPU contains multiple cores, which core will the UEFI firmware, and UEFI bootloader, and OS kernel all execute on?
The BSP and his jiving APettes
‘Symmetric’ multiprocessing is only so symmetric, and it turns out that x86 SMP systems do indeed differentiate a bit between their different cores. In particular, the core that’s chosen to run the initial thread of execution (for the UEFI environment, etc.) is somewhat special, and has its own special name: the bootstrap processor, or BSP. All other cores, which are left in a sleeping state until the OS is ready to boot them, are referred to as application processors, or APs.
How is the BSP selected from the pool of available cores? Great question!
Following a power-up or RESET of an MP system, system hardware dynamically selects one of the processors on the system bus as the BSP.
Following reset in multiprocessor configurations, the processors use a multiple-processor initialization protocol to negotiate which processor becomes the bootstrap processor. […] For further information, see the documentation for particular implementations of the architecture.
OK, hardware magic. Got it.✱
✱ Note
Regardless, the system selects a BSP, the UEFI firmware will catapult it from 16-bit Real Mode to 64-bit Long Mode, and axle’s UEFI bootloader will finally gain control of the system. It’ll load axle’s kernel, which will continue the boot process. Until early January 2023, the story would stop here: axle would quickly context switch different tasks in and out on the BSP, living in blissful ignorance of the APs sitting idle on the system.
Reading convoluted specs: The neverending story
But of course, all free time must come to an end. I’ve had an itch for years to make axle SMP-aware, and fresh off the back of some application-level programming of reimplementing awm in Rust✱, I had a desire to sink my teeth into something lower-level. Away we go!
✱ Note
Firstly, before we can actually boot any APs, we’ll need to parse some metadata to find out some information about them (such as how many APs there are and their internal IDs). To do this, we need to parse some ACPI tables. ACPI, or ‘Advanced Configuration and Power Interface’, is a specification intended to centralize power management of different pieces of hardware. Why were power management structures deemed to be the best place to shoehorn critical info about CPU topology? I will remind you that axle is an x86 OS, and x86 is pain.
Okay! Parsing ACPI tables it is. Where do we find them?
The root ACPI table pointer, or in ACPI parlance, RSDP (root system description pointer), is actually one of the pieces of information that the UEFI firmware’s memory map provides to the UEFI running environment. Let’s update axle’s bootloader to retain a pointer to this and pass it along to the kernel✱.
✱ Note
By this point I had been writing a lot of Rust in application-level code, and the thought of writing new kernel-level parsing code in C was a sad one. Therefore, I also took the opportunity to introduce Rust to the kernel, and used it for most of the new SMP code.
Parse enough ACPI tables and eventually you’ll find a listing of the processors on the system, along with their APIC IDs. What’s an APIC, you may ask? While primarily a common misspelling of ACPI, APIC actually signifies the advanced programmable interrupt controller, of which each CPU core in the system has one✱.
✱ Note
✱ Note
APIC ID #3 is connected to CPU ID #1). Lots of hardware interfaces accept either an APIC ID or a CPU core ID: the possibility space for bugs is rich and scintillating.Why in the world do ACPI and APIC, which are vaguely related, since the ACPI tables contain APIC metadata, but otherwise have nothing to do with each other, named so similarly? Once again, the uncanny ability of the x86 ecosystem to name poorly rears its ugly head.
Booting an AP
Now that we know about the APs in the system, it’s time to bring them up and have them start executing code! To wake a sleeping AP, OS code running on the BSP must send a specific series of special interrupts to the AP’s APIC✱. One of these interrupts (the startup inter-processor interrupt, or SIPI) carries a smidge of data, and this data informs the AP what address it should start executing code from. This address must be a physical frame boundary below the 1MB mark, since the AP will start in 16-bit Real Mode.
✱ Note
INIT-SIPI-SIPI, with specific delays in between each interrupt. I won’t go into the details here, but suffice to say it’s weird that the SIPI is sent twice. Further reading awaits you.Wait, what?
Yes, that’s right. Although one of the selling points of UEFI is that it’ll take care of all the nitty-gritty mode switching for you, this only applies to the BSP. Once you want to start booting APs, you’ll need to go back and learn all the details of how to boot a processor from Real Mode, through Protected Mode, all the way up to Long Mode. Feel like false advertising? I certainly thought so.
In any case, we’ve come this far, so we might as well get our hands dirty. Thankfully, things once again aren’t that bad as long as you take the time to decipher what needs to be done.
Our first complication quickly presents itself. While the address specified by our SIPI needs to be a frame boundary below the 1MB mark, our build system has no ’native’ way to specify a physical load address for a binary segment✱. How can we ensure that we have some code ready-to-go at an appropriate address for the APs to boot from?
✱ Note
Here’s how I solved it. Let’s select some physical frame within the allowed region (oh, say, 0x8000), and designate it as the super-special AP bootstrap region. We’ll somehow need to get our AP bootstrap code into this frame.
I introduced a new and special step to the build system: there’s a new standalone program, ap_bootstrap.s, which will be the entry point for all APs when they boot. The UEFI environment provides a filesystem for UEFI apps to use (for example, the bootloader loads the kernel from EFI/AXLE/KERNEL.ELF), so we can ship this AP bootstrap program as EFI/AXLE/AP_BOOTSTRAP.BIN and have the bootloader map it at any physical memory location that’s convenient. The bootloader can then pass the AP bootstrap’s load address, and its size, to the kernel✱.
✱ Note
The kernel’s physical memory manager then has a bit of logic that says “Frame 0x8000 is super special - never let the general-purpose frame allocator use it!”, and later on the kernel will copy the bootstrap artifact from wherever the bootloader placed it to the special 0x8000 frame that our AP startup vector points to.
This program has the hallowed responsibility of jumping from Real Mode to Long Mode (with a short layover in Protected Mode, of course). Since the start of the code will be running in 16-bit mode and the end in 64-bit mode, it’s quite a fun read - the mnemonics and register names keep on growing as you move further down the file✱.
✱ Note
It turns out that it’s quite useful for the kernel proper to pass data to this bootstrap program✱. Let’s reserve one more frame, 0x9000, and place the different pieces of data that we want to provide to the bootstrap program at mutually understood offsets.
✱ Note
Once the AP is happily swimming in Long Mode, and with a virtual address space that matches the kernel’s expected environment✱, we can jump into the kernel code and ‘join’ the AP to the kernel program. Our next goal is hooking things up such that we can schedule tasks on the AP.
✱ Note
Identity crisis! in the CPU
Before we can get there, though, we’ll need some kind of per-core storage. This is useful for many reasons: one is so that each core has a place to store its own ID. Where can we put this private storage, though?
One way is to maintain a special virtual memory page within the kernel’s virtual address space that contains different data depending on the active CPU core. This sounds great in theory, until you hit the fun bugs that arise from when you move a task that was spawned from one core to another core, and all of a sudden you have two cores arguing over who’s the real CPU #0. We’ll need to be careful to swap out the core-specific data page whenever migrating a virtual address space from one CPU core to another.
We’ll also need some way to deliver interrupts to each CPU. While the PIC was sufficient for single-core-land, the multicore revolution brought with it new interrupt routing mechanisms. Now, there’s a✱ global IOAPIC, as well as a per-core local APIC, as mentioned in brief above. These local APICs serve the dual function of routing interrupts and serving as one of the root communication channels for CPUs✱. To facilitate all of this, I had to disable the legacy PIC, and switch axle’s interrupts mechanism from using the PIC to the IOAPIC and local APICs✱.
✱ Note
✱ Note
✱ Note
Timekeeping
Speaking of legacy hardware, the traditional way to track the passage of time in the Platonic ideal PC is with use of the PIT, or programmable interval timer. This is a little crystal that vibrates very quickly. Each time it oscillates it knocks into the edge of the CPU, which jiggles to one side. This jiggling causes excess electrons to spill onto one of the CPUs interrupt lines, giving us a nice periodic interrupt that the kernel can use to track the passage of time✱.
✱ Note
Kernels conventionally✱ use the PIT as the proverbial heel-spur to drive preemptive multitasking. In addition to the PIT interrupt handler incrementing a counter to track the passage of time, the handler will also kick the scheduler if it sees the current task has been running for too long.
✱ Note
This doesn’t work so well when we have multiple CPUs that all need preemption, though. Trying to distribute a single timer resource across multiple CPUs would result in a lot of contention and waste, so the benevolent hardware gods gave us a new boon: the local APIC timer.
*record scratch*
Yes, in addition to its ostensible function as an interrupt controller, as well as its moonlighting as the place-to-go to identify the different CPU cores from the ACPI tables, each local APIC also contains a new timer that runs at a much higher frequency than the legacy PIT: the local APIC timer. In fact, the local APIC timer actually runs at the CPU core’s frequency✱!
✱ Note
This sounds great at first, but this is not a stable and consistent clock: depending on power management and various other criteria, cores can clock up or clock down, varying the rate of timekeeping (i.e. how long a tick takes, in real-world time). We’ll need another, more stable time source to occasionally synchronize the LAPIC timer.
For now, since axle doesn’t intentionally vary CPU frequencies, I’m taking an initial sample of how many LAPIC ticks occur over a few PIT ticks when configuring each APIC and leaving it at that. I’ve then switched the source for kicking off preemptive context switches to each CPU’s local APIC timer interrupt handler.
Since it’s trivial to tell the LAPIC timer to fire at some date in the future, I’m now just arming it to fire just once when the current task needs to be preempted, rather than firing thousands of times per second like the PIT does.
Remember how every x86 CPU, for all time, starts up in an entirely redundant 16-bit mode? Note the echoes here: every single x86 package contains the circuitry and hardware to provide the legacy PIT functionality, even though the PIT will be entirely ignored by any modern OS✱.
✱ Note
Distributing work
Things are shaping up pretty well! We’ve detected the other cores, have initialized all the hardware components we need, and have migrated from some legacy technologies to their newer alternatives. Now it’s time to make sure we’re using these new resources efficiently, by scheduling different tasks amongst all the CPU cores we now have available.
To make sure we’ll have a pool of work to draw from, the BSP will launch the file server as its final act before becoming an anonymous core and joining up with the AP code path. The file server will read the configuration file containing the programs to launch on startup, and will spawn a task for each of them.
Despite our best efforts, though, our cores will occasionally have nothing to do. While we already had a global idle task in the unicore implementation, we’ll now need a separate idle task for each CPU core.
Of course, spinning up all the work in the world isn’t going to allow the APs to do much unless the scheduler is able to migrate tasks between CPU cores to distribute work. Migrating to another core is considered an expensive operation so many schedulers assign a ‘CPU affinity’ (i.e. the core that a task would like to remain on), but I’m not bothering too much with that at the moment.
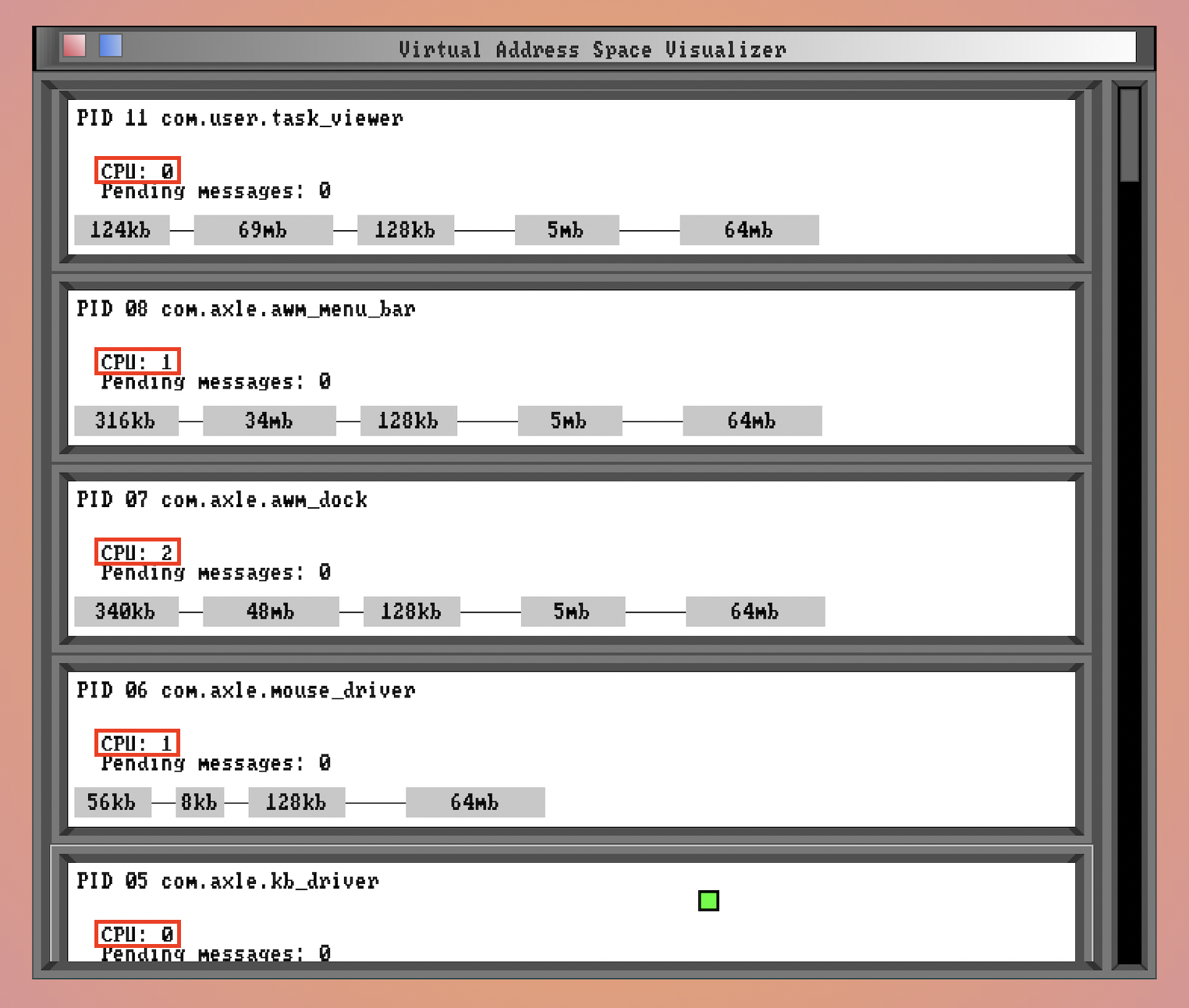
Task contexts will now need to store the CPU ID they’re running on, and the scheduler will need to be careful not to schedule a task that’s already running on another CPU core✱.
✱ Note
Lastly, we’re working with a codebase that wasn’t written with concurrent kernel execution in mind, so we’ll have some bugs to fix and short-lived spinlocks to insert.
And with that, axle is now an SMP-capable OS. I hope you enjoyed the ride, and please remember to take all your belongings with you before exiting the blog.